

To write a Spark program it is crucial to first understand Apache Spark’s underlying execution model. In this blog post, we will talk about some of the key aspects we need to consider while writing the Spark code to execute the job efficiently. We will also discuss the best practices and optimization tips for Apache Spark to achieve better performance and cleaner code, whilst covering:
- Transformations
- Partitioning
- Memory Management
Transformations
The most frequent performance problem when working with the Spark Core (RDD) API, is using transformations which are inadequate for the specific use case.
Let’s take a look at these two definitions of the same computation:
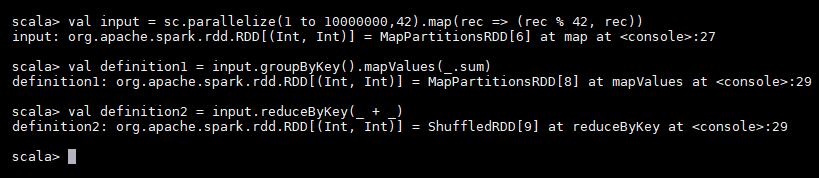
[java]val input = sc.parallelize(1 to 10000000,42).map(rec => (rec % 42, rec)) val definition1 = input.groupByKey().mapValues(_.sum) val definition2 = input.reduceByKey(_ + _)[/java]

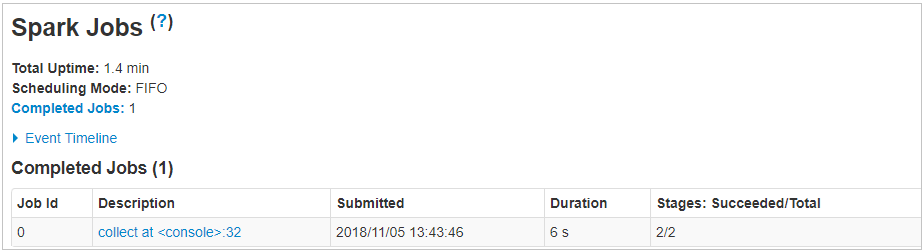
[java]definition1.collect.foreach(println)[/java]
When I call action in spark for definition1(rdd), it took around 6 seconds for execution.

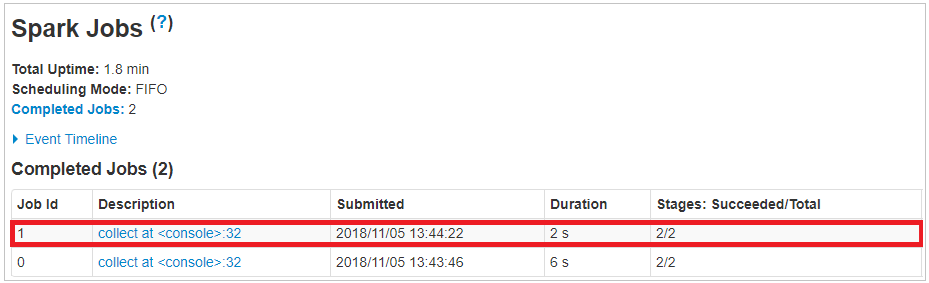
[java]definition2.collect.foreach(println)[/java]
When I call second definition, it took around 2 seconds for execution. The second definition is far quicker than the first one because it handles data more efficiently in the context of our use case by not collecting all the elements needlessly.
The rule of thumb here is to always work with a minimal amount of data at the transformation boundaries. The RDD API does its best to optimize background stuff like task scheduling, preferred locations based on data locality, etc. However, it doesn’t optimize the computations themselves. In fact, it is literally impossible for it to do that as each transformation is defined by an opaque function and Spark has no way to see what data we are working with and how.
Partitioning
Resilient Distributed Datasets are the collection of various data items that are so huge in size, that they cannot fit into a single node and have to be partitioned across various nodes. Spark program automatically partitions RDDs and distributes the partitions across completely different nodes. A partition in spark is a logical division of data stored on a node in the cluster.

[java]Val test = sc.parallelize(1 to 200) test.partitions.size[/java]
You need to call “rdd.partitions.size” or “rdd.partitions.length” or “rdd.getNumPartitions” to check the number of partitions.
Custom Partitioning

[java]val test = sc.parallelize(1 to 200).coalesce(3)[/java]
RDDs in Apache Spark are the collection of partitions. RDDs are automatically partitioned in spark without human intervention, however, at times the programmers would like to change the partitioning scheme by changing the size of the partitions and number of partitions based on the requirements of the application. For custom partitioning, developers have to check the number of slots in the hardware and how many tasks an executor can handle to optimize performance and achieve parallelism.
The best way to decide the number of partitions in an RDD is to create the partitions equal to the number of cores in the cluster so that all the partitions will process in parallel and the resources will be utilized in an optimal way.Partitioning will also help parallelize distributed data processing with minimal network traffic for sending data between executors.
[java]val rdd= sc.textFile("/test", 5)[/java]
The above line describes that, it will create an RDD named textfile with 5 partitions. Suppose you have a cluster with 4 cores and each processor needs to process for 5min. So, for the above RDD with 5 partitions, 4 partitions will work in parallel with 4 cores and the 5th partition process will start after any of those resources remain idle. This task may take around 10 minutes of time, so we take number of partitions equal to number of cores.
If an RDD has too many partitions, then task scheduling may take more time than the actual execution time. In the contrary, having too less partitions are also not beneficial as some of the worker nodes could just be sitting idle resulting in less concurrency. This could lead to improper resource utilization and data skewing i.e., data might be skewed on a single partition and a worker node might be doing more than other worker nodes. Thus, there is always a trade off when it comes to deciding on the number of partitions.
- sc.parallelize(1 to 100).count
If we run the above line it will take default 8 partitions to give the result in 0.3 sec.
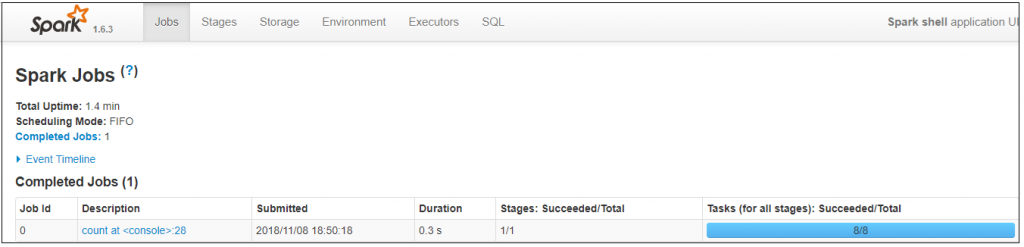
- sc.parallelize(1 to 100, 2).count
In the above line we customized the number of partitions to 2.
Spark also has an optimized version of repartition() called coalesce() that allows avoiding data movement, but only if you are decreasing the number of RDD partitions.
Repartition – It is recommended to use repartition while increasing number of partitions because it involves shuffling of all the data.
Coalesce – It is recommended to use coalesce while reducing number of partitions. For example, if you have 3 partitions and you want to reduce it to 2 partitions, Coalesce will move 3rd partition Data to partition 1 and 2. Partition 1 and 2 will remain in same container, but repartition will shuffle data in all partitions. So, the network usage between executor will be high and impact the performance. Performance wise coalesce performance is better than repartition while reducing number of partitions.
Memory Management
Apache Spark is verified to be a great engine for processing massive datasets of terabytes or larger. The large amounts of configurations required to run different workloads at scale will make it unstable, if done improperly.
One of the common issues users face when configuring and running spark applications is deciding number of executors or number of cores they should use for their application. Typically, this process is completed with trial and error, and it doesn’t tell us where to look for further improvements.
Things to consider in Memory Management:
- executor-memory (–executor-memory)
- driver-memory (–driver-memory)
- executor-cores (–executor-cores)
- num-executors (–num-executors)
While specifying num-executors, we need to make sure that we leave aside enough cores (~1 core per node) for these daemons to run smoothly.
Example:
spark-submit –class xxx.xx.x –num-executors 2 –executor-cores 2 –executor-memory 5g ….
–num-executors, –executor-cores and –executor-memory.. These 3 params play a really vital role in spark job performance as they control the amount of CPU & memory your spark application gets. This makes it crucial for users to know the right way to configure them. Hope this blog helped you in gaining that perspective.
Summing Up
Consequently, we need to consider all these elements, like usage of adequate transformations, partitioning and memory management to improve the performance of the Spark job. Hope you now have a fair understanding of the key factors involved in creating a performance-efficient Spark job.
Evoke’s Big Data Solutions
Evoke offers a complete spectrum of big data and analytics solutions designed to help enterprises improve decision-making capabilities, increase business productivity and create significant business value. We have established a Data Center of Excellence (DCoE) that consists of more than 60 experienced professionals with versatile capabilities in data management and data analytics space. With our deep expertise and hands-on experience in designing and implementation of big data solutions, we are enabling enterprises to manage and analyze data to gain a competitive edge. To know more about our big data solutions, contact us today!
Author
 |
Sai Kumar Akula is a Technical Associate at Evoke Technologies and has over 4 years of experience in Big Data technologies. He is a certified Spark and Hadoop developer and well-versed with technologies like HDFS, Map Reduce, Hive, Pig, Spark Core, Sqoop, Nifi, Solr, HBase, Kafka, Core Java, etc. When he is not at work, he is spending time with his family and on the lookout for learning new things. |