

The buying and selling of goods on eCommerce websites have sky rocketed over the decades. One of the main reasons for this exponential growth is the ease of getting things done while sitting at home. Other factors that attract the audience are discounted prices and offers due to direct selling, reduced retail expenses, and wholesale profit margins.
Optimizing prices and profits based on demand is a significant topic that every eCommerce business comes across. However, product images are the forefront factor that attracts and builds trust in customers buying a product.
This blog majorly covers the estimation of ‘product images influence’ on eCommerce sales and prices. Considering data privacy and protection, the footwear data used in this blog is largely simulated and manipulated. The primary objective of this blog is to get the classification of the Product Images. The secondary objective is to get the magnitude/influence of the predicted class over sales and prices. The predicted classes include:
- Footwear with model/celebrity image – Category1
- Footwear with wearing look (legs) – Category2
- Only product display image – Category3

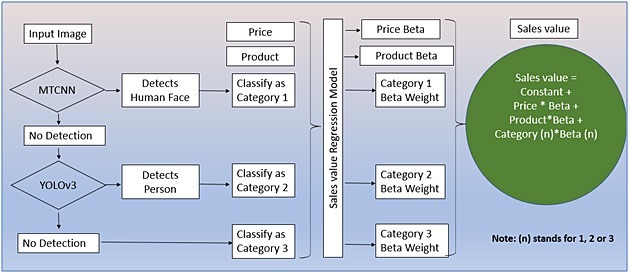
Pipeline & Image Classification with Machine Learning
To get the correct category of the input image, conditional statements with two pretrained models were used:
- MTCNN (Multi-Task Cascaded Convolutional Neural Network): Once input image is selected/loaded, MTCNN tries to detect a human face in the body. If it detects the human face, the input image would be classified as category 1 (Product on a model image). Otherwise, the input image is moved to the Yolov3 pretrained model.
- Yolov3: Yolov3 pretrained model tries to detect a person or part of a person in the input image. Yolov3 has a pretrained class called ‘person’. Even a part of the body can be detected and classified as ‘person’. Therefore, if a person is detected it would be classified as category 2 (Part of the model’s body image).
- Finally, if there is no detection in either of the pretrained models, it would be classified as category 3 (Only product display image).

Figure: Flowchart of conditional statements to get the category of the image
MTCNN Steps
When an input image is selected/loaded, it first moves to MTCNN and tries to detect the face of a person. This first model is used to detect category 1 (Footwear with model/celebrity image). MTCNN checks for five facial landmarks on the image to find a face. These five facial landmarks are – the nose, two eyes, and ends of the mouth.
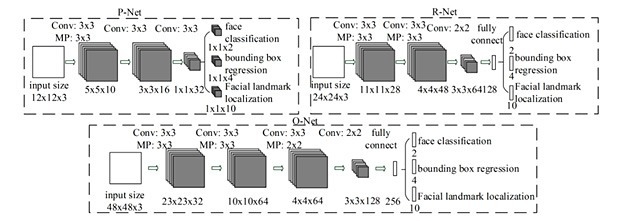
Working of MTCNN consists of three stages: P-Net (to predict bounding boxes), R-Net (to refine the bounding box coordinates), and O-Net (to produce the final output).
MTCNN Stage 1
Proposal Network (P-Net): Using P-Net, the bounding box location would be detected, and, in our case, it is face detection. The following steps undergoes in this stage:
-
- Load the category 1, 2, 3 images to MTCNN to generate different copies of different sizes.

Figure: Pyramid of scaled images - These different scaled images are fed to P-Net to parse kernel of size 12*12 to detect faces in each scaled image.

Figure: Kernel parsing over the image - All the results from different levels of scaled images are combined and the bounding boxes with lower confidences are eliminated.

Figure: Overlapped Bounding boxes - The Non-Maximum Suppression (NMS) method is used to remove the overlapping bounding boxes and the remaining bounding boxes coordinates are scaled to the original input image size.
- Bounding boxes are reshaped to square and passed to the next stage (i.e., R-Net).
- Load the category 1, 2, 3 images to MTCNN to generate different copies of different sizes.


MTCNN Stage 2
Refine Network (R-Net): Using R-Net, the coordinates of bounding boxes are calibrated for refined face detection. The following are the steps:
- Only bounding boxes values of images inside the frame are taken into array and values of images out of frame are treated as 0.
- Scale the images to sizes and feed it to R-Net to perform the same steps as in the previous stage.
- Only one bounding box that is more refined and accurate is sent to the next stage.

Figure: Output from R-Net
MTCNN Stage 3
Output Network (O-Net): Applying O-Net to display output with five facial landmarks on the image. It aims to add definition to the face and outputs five facial landmarks on the face.
- Evaluate the results from stage 2 and output the standardized bounding box coordinates and facial landmarks on the original image size.
- The final output from MTCNN will be a list form consisting of – coordinates of the bounding box, confidence score followed by coordinates of five facial landmarks.

YOLOv3 Step
For the selected/loaded image, if MTCNN has not predicted the face, then the Yolov3 model is triggered to detect if a person or a part of a person is available in the loaded image. Yolov3 is used to detect the second category (Footwear with a wearing look (legs)).
You Only Look Once (YOLO) is a well-known object detection and classification model. YOLO version 3 (Yolov3) is a pre-trained model, that is trained on the coco dataset. This dataset has a total of 80 classes with class ‘person’ as one of the classes which is the target class here. A total of 118,287 train images and 5,000 val images were used while training. Unlike MTCNN, which requires a face to detect human in an image, Yolov3 can detect human by just detecting any body part.
YOLOv3 output:
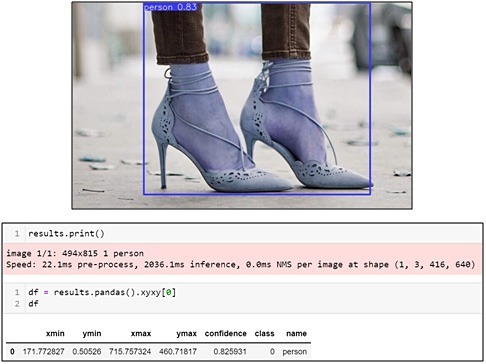
Yolov3 provides the class name ‘person’ along with the bounding box coordinates when there is a person in the image. In the absence of a person, an empty dataframe is created.
Finally, if there is no prediction from both the models – MTCNN and yolov3, the input image will be directly classified as category 3 ‘Only product display image’.
Final Outputs
Below is the image of classification results taken for each image from their respective pretrained models.

Connecting final outputs and sales: Regression beta weights of the images are the key factors for sales prediction. Each product is marketed in three forms – category 1 (Footwear with model/celebrity image), category 2 (Footwear with wearing look (legs)), and category 3 (Only product display image).
Sales Regression Model Equation

Wrapping Up
Based on this blog, we have made the following conclusions:
- Customer shopping patterns have drastically changed, and customers are keen to grab the deals in online shopping.
- Product images loaded corresponding to product bookings are playing as one of the key factors for customer attraction.
- The input image loaded/selected by the online seller influences 5% to 12% of product sales considering other factors such as the price for a wide variety of products. We noted 9% sales influence for ‘Product1’, if ‘Product with Model/Celebrity’ is used as stated above.
Thus, Price, product names, etc., are considered as the influencers of product sales. Moreover, the Images loaded for online shopping have become another key factor/influencer for product sales.
Authors
 |
Chennakesh Saka is working as a Data Science Manager with Evoke Technologies. He holds 11 years of experience in Statistical Models, Machine Learning, Deep Learning, and Text based modelling. He is a technology enthusiast who has served diverse industries including Banking, Retails, Irrigation, and Pharma. | |
 |
Tejaswini Kumaravelu is a Trainee Data Scientist at Evoke Technologies. She holds strong technical knowledge and hands on experience in Machine Learning and Deep Learning Model developments. In her spare time, she tutors orphans, and writes technical blogs and research papers. |