Empower Your Business with Cutting-Edge Data Engineering Consulting Services
Every company needs an efficient way to source, interpret, and consume data. Evoke provides Data Engineering Consulting Services that help businesses unlock the full potential of their data through expert engineering practices.
For many enterprises, data estates are a patchwork of legacy applications, cloud-based systems, data in spreadsheets, social media data, streaming data from sensors, etc. Many of these data estates are fragmented, leading to organizations being data-rich but insight-poor.
At Evoke, our Data Engineers help companies navigate these challenges and align business goals through intelligent, data-driven insights. Our team analyzes structured, semi-structured, and unstructured data with the right processes, technologies, and tools, providing end-to-end data engineering services for the complete data lifecycle.
We also provide data engineering services for enterprises, assisting in data modernization to create platforms that are modular, flexible, secure, cost-effective, and well-managed, while preparing new innovations. Below is an overview of our comprehensive Data Engineering offerings:
Our Services Summary
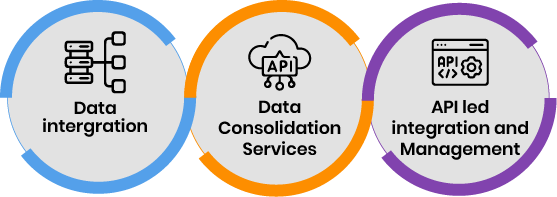
Evoke provides Data Engineering Consulting Services across 3 key areas
- Data Integration/Data Migration
Our data engineering services ensure seamless data integration and migration, helping businesses move their data efficiently between systems. - Data Consolidation Services (Extraction, Transformation, and Loading of Data into Data Lakes, Data Warehouses, and Databases)
- API-Led Migration/API Management Services
Data Integration Service
With over 19 years of experience, we have extensive expertise in cross-platform integration, from on-premises to cloud or vice versa. Our data engineering services
company uses the latest tools, frameworks, and platforms to help integrate complex data across your systems.
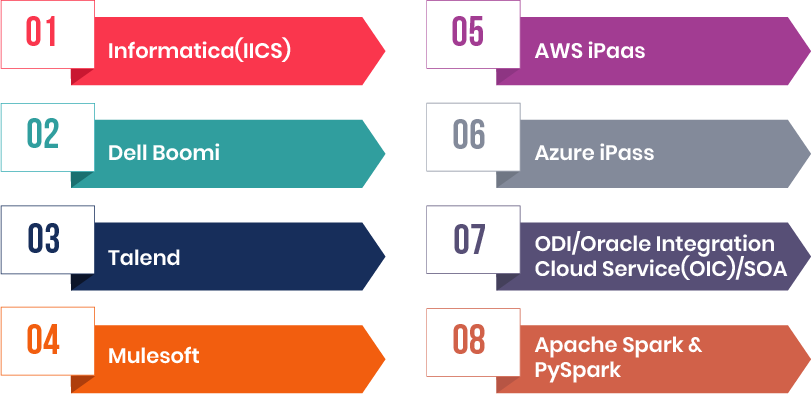
Evoke has done many data and apps integration projects using Informatica Cloud/Power Centre, Boomi, Talend,Mulesoft, AWS iPaaS, Azure iPaas, Python &PySpark etc. Our Engineers have built many data pipelines from data sources to target storage/applications.
Evoke Data Engineers help our customers in developing near Real-time data pipelines to provide decision makers with more current
data. Our Modern data pipelines approach rely on the cloud to enable customers to automatically scale compute and storage resources up or down. Usually for Modern data pipelines, we design a distributed architecture that provides immediate failover and alerts users in the event of node failure, application failure, and failure of certain other services. It also has advanced checkpointing capabilities that ensure that no events are missed or processed twice.
Data Consolidation Service
Evoke “Data Consolidation” is the classic data integration process leveraging ETL(extract, transform and load) which helps in combining data from disparate sources, transforming & aggregating after removing its redundancies within a single data store like a Data Lake OR Data Warehouse OR Database.
(a) Data Lake Implementation
- Evoke has helped our customers in building their Data Lakes on Cloud OR On-Prem servers which involved multiple ELT processes. Evoke has expertise in implementing Data Lakes on:
(1) AWS
(2) Azure
(3) Google
(4) Databricks
(5) Snowflake.
(b) Data Warehouse Implementation
- Evoke has developed many Data Warehouses for our customers over the years and our engineers have become expert in dimensional modelling.
- Currently, Evoke is involved in two Data Warehousing implementations. Out of which one is very large consisting of 400 + ETLs,30 DataMart’s using 30 + Source Systems,900 Tables,190 Views. We are doing this for one of the largest providers of Registered Agent, UCC search and filing, compliance, and entity services.
- Our Data Engineers are very experienced in developing Cloud based Data Warehouses like in AWS/Azure/Snowflake. Because traditional enterprise data warehouses are experiencing huge data explosion, data latency and increasing cost hence many customers are moving tomodernized cloud data warehouse. As part of this, modernized cloud data warehouse can handle high volumes of structured and unstructured data using agile methodology to unify disparate data sources in customer’s technology ecosystem.
- We are also working on an Azure based Data Warehouse for a large Organic farms company in USA. There are around 50 Fact tables and 30 Dimensions built in the Data Warehouse with around 200 Data Factory Pipelines(ETLs). Azure Data Factory,Azure Synapse Analytics(dedicated SQL Pool), Azure SQL, PowerBI etc. are used in this implementation.
(c) Database to Database migration Service
Database to database migration is part of our Data Consolidation service where data is migrated from one database to another one as part of the data consolidation effort. There are various kinds of migrations but the 2 important ones that we frequently do are:
- Big Bang Database Migration
- Zero-Downtime Database Migration
Examples of some of the tools that we use for database migrations are
- Database Migration Workbench
- Database Migration Service
- Schema Conversion Tool (creates the migrated schemas on the target database)
- ora2pg to migrate an Oracle database or MySQL database to a PostgreSQL-compatible schema.
- SQL Server Migration Assistant (SSMA) for Oracle

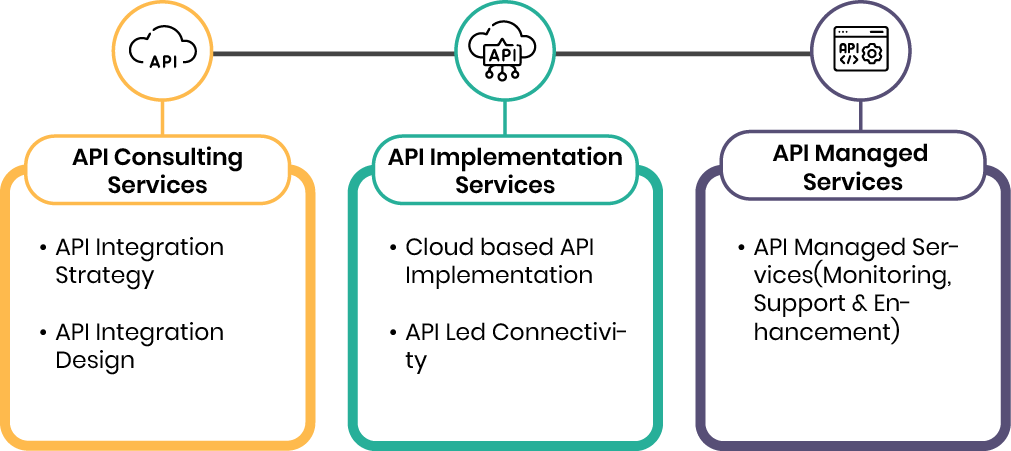
API Led Integration and API Management
Our Data Engineers Provides Following API Services For Our Customers
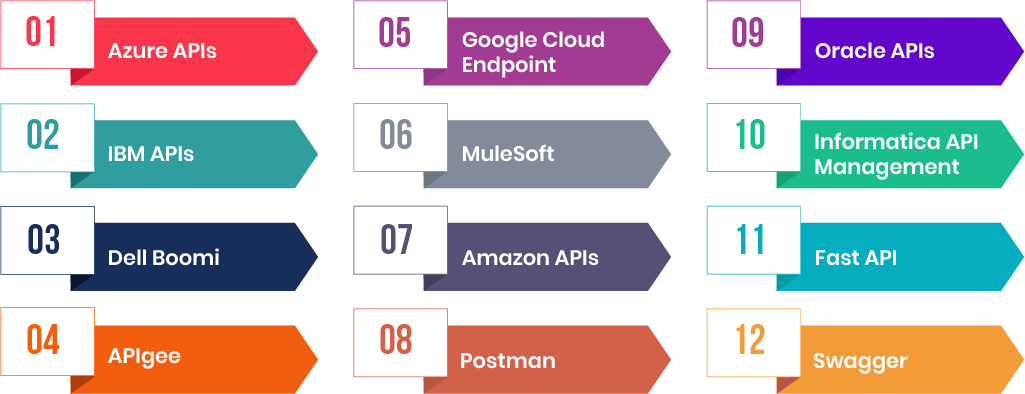
We are using various API tools as part of our Data Integration and Application integration effort in various projects.
Below is a list of the key API tools that we usually use for our customers